Paper
Sun, Kunyang, et al. "SynLlama: generating synthesizable molecules and their analogs with large language models." ACS Central Science 11.11 (2025): 2108-2120.
https://pubs.acs.org/doi/full/10.1021/acscentsci.5c01285
Github
THGLab/SynLlama: Code Space of SynLlama
Abstract
Generative machine learning models for exploring chemical space have shown immense promise, but many molecules that they generate are too difficult to synthesize, making them impractical for further investigation or development. In this work, we present a novel approach by fine-tuning Meta’s Llama3 Large Language Models (LLMs) to create SynLlama, which generates full synthetic pathways made of commonly accessible building blocks and robust organic reaction templates. SynLlama explores a large synthesizable space using significantly less data and offers strong performance in both forward and bottom-up synthesis planning compared to other state-of-the-art methods. We find that SynLlama, even without training on external building blocks, can effectively generalize to unseen yet purchasable building blocks, meaning that its reconstruction capabilities extend to a broader synthesizable chemical space than those of the training data. We also demonstrate the use of SynLlama in a pharmaceutical context for synthesis planning of analog molecules and hit expansion leads for proposed inhibitors of target proteins, offering medicinal chemists a valuable tool for discovery.
[Problem]
- 기존 생성 모델들이 생성한 많은 분자들이 합성이 너무 어려워 추가 연구나 개발에 실용적이지 않다.
[Solution]
- building block과 reaction template로 full 합성 pathway를 생성
[Contribution]
- 적은 데이터 학습
- 학습 데이터에 없던 building block으로도 확장 가능
Concept
[1] Synthesizable chemical space
- 합성 가능한 분자들의 집합 정의
- 두 가지 요소 구성 (Building Blocks [BBs]: 시약 회사에서 살 수 있는 출발 물질, Reaction templates [RXNS]: 유기 반응 규칙)
Q. 그래서 Bulidning block이랑 Reaction template가 뭐지?
Reference:
Chemical Spaces • Ultra-Large Compound Collections by BioSolveIT

- 그림 처럼 미리 검증된 유기 반응과 building block을 데이터로 정리
- 논문에서 사용한 dataset
| Data | details |
| Training BBs | Enamine Aug 2024, ~230k개 |
| Testing BBs | Enamine Feb 2025 신규, ~13k개 |
| RXN1 | 91개 반응 템플릿 |
| RXN2 | 115개 반응 템플릿 |
- BBs × RXNs 조합 = 10³⁰ 분자 표현이 가능, 최대 5 step 합성까지 허용
[2] Represents
- 분자, BBs, Intermediate: SMILES (string)
- reaction: SMART (string)
[3] Time split
- Train, test를 시간 기준으로 분리
- Aug 2024 BBs → train
- Feb 2025 신규 BBs → test
- Why? 실제로 새로운 BBs에 일반화되는지 검증
Method & Result
[1] Training data 생성

생성 과정:
1. RXN 템플릿을 확률적으로 선택
2. 해당 RXN에 맞는 BB들 중 랜덤 선택
3. 반응 실행 → Intermediate 생성
4. Intermediate에 적용 가능한 다음 RXN 탐색
5. 반복 (최대 5 step까지)
[2] Supervised fine-tuning

- Base model:
| Model | parameter | Data | GPU time (A40) |
| Llama-3.1-8B | 8B | 100k, 500k | 40h, 240h |
| Llama-3.2-1B | 1B | 500k, 2M | 60h, 240h |
결론은 SynLlama-1B-2M, 8B-500k랑 1B-2M이 비슷한 GPU 시간을 소모하는데, 벤치마크 성능 비슷하고 inference 속도는 1B가 훨씬 빠르기 때문이다.
- Fine-tuning detail
Supervised Fine Tuning protocol. After preparing the reaction data and prompt response pairs from the training chemical space, we fine-tune Llama-3.1-8B (8 Billion pa rameters) and Llama-3.2-1B (1 Billion parameters) using the Axolotl package for 1 epoch. LLMs with more parameters require more resources to train and use, but they also typically perform better on a variety of tasks, which we consider in Results. For our SFT approach, we apply Low-Rank Adaptation (LoRA) with a rank of r = 32 and α = 16 to the linear layers of the model. We use FlashAttention-2, with the Adam optimizer, cross-entropy loss, and a cosine learning rate scheduler with a maximum learning rate of 2 × 10⁻⁵ .
- Prompt - response 구조

TEMPLATE = {
"instruction": "You are an expert synthetic organic chemist. Your task is to design a synthesis pathway for a given target molecule using common and reliable reaction templates and building blocks. Follow these instructions:\n\n1. **Input the SMILES String:** Read in the SMILES string of the target molecule and identify common reaction templates that can be applied.\n\n2. **Decompose the Target Molecule:** Use the identified reaction templates to decompose the target molecule into different intermediates.\n\n3. **Check for Building Blocks:** For each intermediate:\n - Identify if it is a building block. If it is, wrap it in <bb> and </bb> tags and save it for later use.\n - If it is not a building block, apply additional reaction templates to further decompose it into building blocks.\n\n4. **Document Reactions:** For each reaction documented in the output, wrap the reaction template in <rxn> and </rxn> tags.\n\n5. **Repeat the Process:** Continue this process until all intermediates are decomposed into building blocks, and document each step clearly in a structured JSON format.",
"input": "Provide a synthetic pathway for this SMILES string: SMILES_STRING",
"output": "{\"reactions\": [REACTIONS], \"building_blocks\": [BUILDING_BLOCKS]}"
}
- Instruction: 고정된 시스템 프롬프트 ("You are an expert synthetic organic chemist...")
- Input: Target 분자의 SMILES
- Output: JSON 형식 (reactions + building blocks)
[추가] Train 과정에서도 Prompt - response 구조로 유지하면서 학습을 시켰는데, 그림의 Output을 자세히 보면 Retrosynthesis 방향으로 학습하는 것을 알 수 있다.
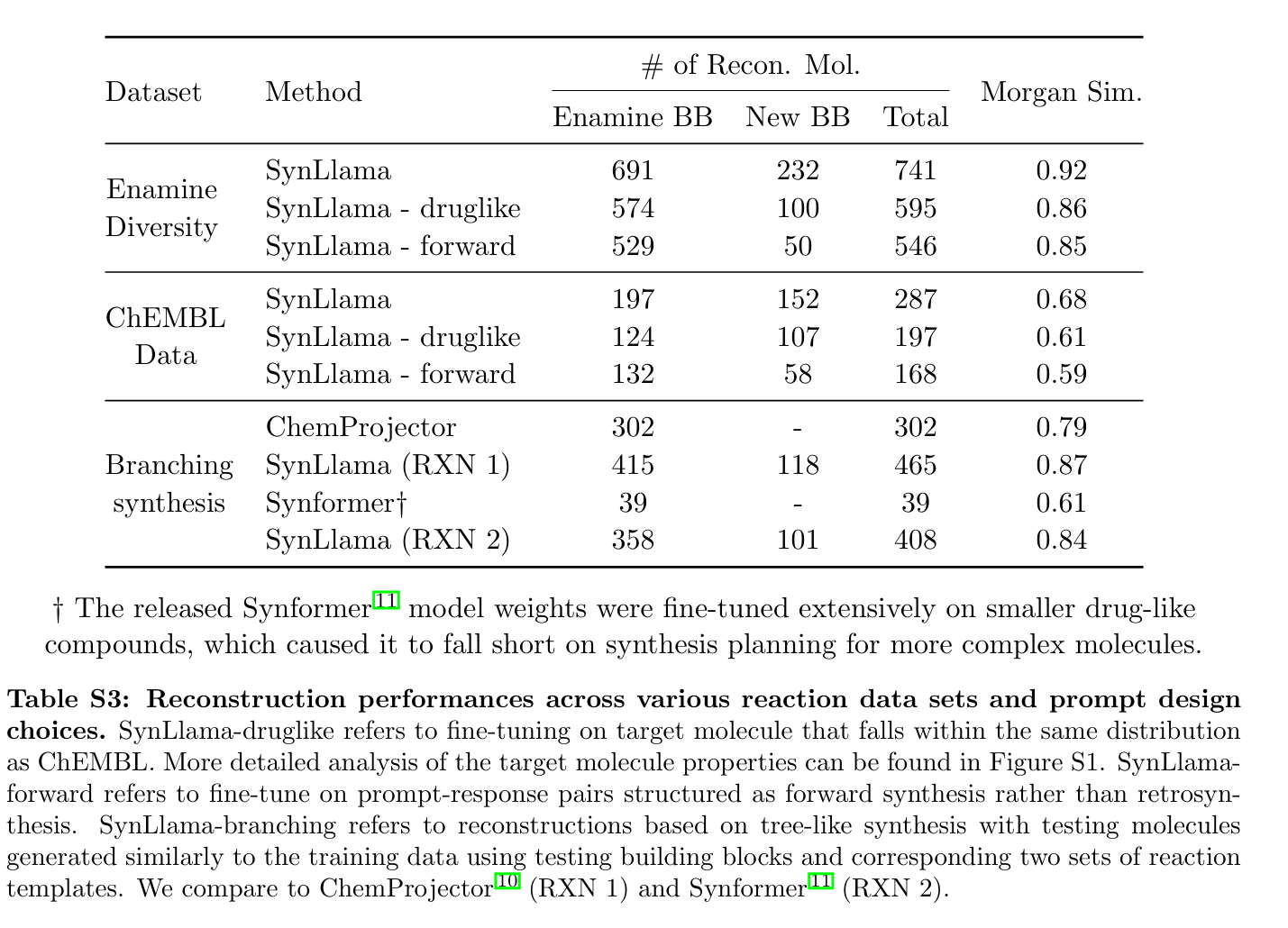
→ forward 구조보다 Retrosynthesis가 더 좋은 성능을 보여준다.
[3] Inference
- Parameters 설정: LLM은 Temperature(T)와 Top-p 조절로 output의 다양성을 컨트롤 할 수 있다.
Reference:

- Sampling 전략
sampling_params_frugal = [
{"temp": 0.1, "top_p": 0.1, "repeat": 1, "name": "frozen"},
{"temp": 0.6, "top_p": 0.5, "repeat": 1, "name": "low"},
{"temp": 1.0, "top_p": 0.7, "repeat": 1, "name": "medium"},
{"temp": 1.5, "top_p": 0.9, "repeat": 1, "name": "high"}
]
sampling_params_greedy = [
{"temp": 0.1, "top_p": 0.1, "repeat": 1, "name": "frozen"},
{"temp": 0.6, "top_p": 0.5, "repeat": 2, "name": "low"},
{"temp": 1.0, "top_p": 0.7, "repeat": 3, "name": "medium"},
{"temp": 1.5, "top_p": 0.9, "repeat": 4, "name": "high"}
]
sampling_params_frozen_only = [
{"temp": 0.1, "top_p": 0.1, "repeat": 1, "name": "frozen"}
]
sampling_params_low_only = [
{"temp": 0.6, "top_p": 0.5, "repeat": 5, "name": "low"}
]
sampling_params_medium_only = [
{"temp": 1.0, "top_p": 0.7, "repeat": 5, "name": "medium"}
]
sampling_params_high_only = [
{"temp": 1.5, "top_p": 0.9, "repeat": 5, "name": "high"}→ Greedy sampling 같은 경우에는 하나의 분자에 대해 10개의 합성 경로가 생성되는 것이다.
[4] Reconstruction Algorithm

- SynLlama의 raw output이 바로 사용 가능하지 않다.
- 예측된 BBs가 실제로 구매 가능한지 확인하고, 아니면 유사한 BBs로 대체해야 한다.
- Nearest Neighbor Search:
1. SMILES 기반: TF-IDF (bigram, trigram)로 string similarity 계산
2. Morgan Fingerprint 기반: 256-bit, radius=2, Tanimoto similarity
(※ 각 RXN 템플릿별로 compatible BB들에 대해 별도의 search tree를 구축해둔다. 효율적)

→ 그림처럼 실제 분자들로 재구성
- BBs searching
1. Enamine BB
2. Molportt 검색 (novel BB지만 구매 가능 여부 확인)
Checking Commercial Availability of Building Blocks via Molport. In Results, we used the Molport platform to check whether a predicted BB is commercially available or not. Initially, we compiled a list of building blocks for searching and used the ‘List Search’ tab in the Molport website (https://www.molport.com/shop/swl-step-1) to check their availability. Once the SMILES strings were entered into the search interface, we set the search criteria to a minimum acceptable quantity of 500 mg and match types restricted to ‘Exact’ and ‘Perfect’ to search in the database of ‘screening compounds’ and ‘building blocks.’ Once the search completed, we downloaded the excel file under the ‘Selected Items’ column from the List Search result tab (https://www.molport.com/shop/swl-requests), which contained both the commercially available compounds and information about the supplying vendors.
→ 구체적인 Molport 검색 방법
[5] Benchmarking

- Instruction Following
1. Valid JSON: 파싱 가능한 출력인가
2. Template Memorization: 학습된 RXN 템플릿을 정확히 사용하는가
3. BB Selection: Reactions 섹션에서 BB를 정확히 추출하는가
- Reaction Chemistry Comprehension
1. Valid SMILES: 생성된 SMILES가 유효한가
2. Matched Reactants: Reactants가 RXN 템플릿 조건에 맞는가
3. Good Products: RXN + Reactants → 예측된 Product가 실제로 나오는가
※ Table1- Result
- Training → Testing 성능 저하가 크게 저하되지 않는다. (unseen BB generation)
- ChEMBL에서 Good Products가 87%로 떨어지는데, 이건 ChEMBL이 다른 chemical space를 점유하기 때문