Active learning
- 모델이 단순히 양이 많은 데이터를 배우는 것에 그치지 않고, 주어진 데이터에 대해 직접 질문을 던질 수 있는 방법
- 학습 알고리즘이 학습할 데이터를 직접 선택할 수 있다면, 적은 데이터로도 더 나은 성능을 낼 수 있다는 것이 핵심
- 알고리즘이 스스로 '호기심을 가지는' 방식
Supervised learning 과 Active learning
- Supervised learning 는 정확한 학습을 위해 수천 개 이상의 labeling 된 데이터가 필요하다.
- 스팸 이메일, 영화 평점 같은 labeling이 쉬운 데이터는 비교적 저렴하게 구할 수 있지만, 음성 인식이나 문서, 이미지, 영상 분류 등 labeling이 어려운 데이터는 비용과 시간이 많이 든다.
이러한 문제를 해결하기 위해서는 어떤 방식을 사용해야 할까?
- (Active learning) labeling에 드는 시간을 줄이기 위해서 모델이 스스로 필요한 데이터에 labeling 을 요청하면 해결할 수 있다.
- Query : 모델이 Oracle(label 붙이는 사람)에게 특정 데이터의 label을 붙여달라고 요청하는 것, 혹은 특정 데이터 그 자체를 의미한다.
- 즉, 스스로 query 할 수 있는 학습 방법이 필요한 것이다.
Active learning 과정

- Labeled Training Set (L) : label이 붙어 있는 학습 데이터셋, 이 데이터는 모델이 학습을 시작하는 기본 자료가 된다.
- Request : 모델이 특정 데이터 포인트의 label을 요청하는 단계, 이 단계에서는 가장 필요한 데이터를 신중히 골라 label을 요청하는 것이 중요하다.
- Action : 모델은 새로 받은 label 정보를 학습에 반영하고, 이 지식을 바탕으로 다음에 label을 요청할 데이터를 선택한다.
예시를 통한 Active learning 개념 설명

- 2차원 데이터를 linear classifier(선형 분류)로 나누는 경우를 가정한다.
- 그림을 봤을 때 이 데이터들은 가운데를 기준으로 수직으로 나누면 두 부분으로 구분될 수 있다.
- 하지만, 소수의 데이터에만 label이 달려 있다면 어디에 경계선을 그어야 할지 쉽게 정할 수 없다.
- 여기서 label을 색깔로 생각하면 이해하기 쉽다. (우리 눈으로 봤을 때는 데이터들이 색깔로 구별되지만, 모델은 label이 있어야 구분할 수 있다.)
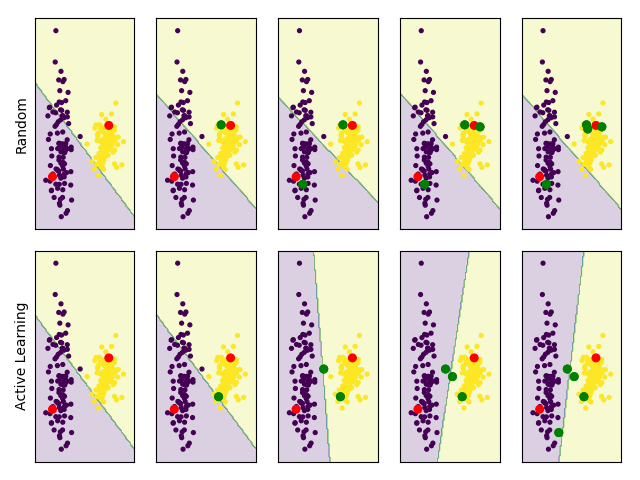
- Active learning 알고리즘 중 하나인 uncertainty sampling과 random sampling을 비교하는 그림이다.
- 두 알고리즘은 데이터 blob(덩어리)에서 처음에 빨간색으로 표시된 하나의 label 포인트를 받고, 이후에 초록색으로 표시된 추가 label 포인트를 순차적으로 요청한다.
- 각 단계마다 label이 있는 데이터셋으로 linear SVM(support vector machine) classifier를 학습시킨다.
- 처음 두 개의 label 포인트만으로는 데이터가 잘 분리되지 않고, 약간 기울어진 경계가 그려지는 것을 확인할 수 있다.
- Random sampling은 밀도가 높은 노란색 blob 안의 포인트들을 주로 선택하는데, 이들은 데이터들의 경계에 대한 정보를 주지 않아 경계선이 거의 변하지 않는다.
- 반면, active learning 알고리즘은 경계에 대한 정보가 많은 데이터들을 선택해 올바른 경계를 빠르게 찾을 수 있다.
결론:
- Active learning 은 labeling 해야 하는 데이터 수를 줄일 수 있다.
- Active learning 은 경계선(Decision Boundary)을 더 빠르게 잘 찾을 수 있다.
- 모델은 헷갈리는 데이터(데이터들의 경계)를 잘 선택해야 올바른 경계를 찾을 수 있다.
Active learning의 종류

1. Membership Query Synthesis
- 모델이 labeling 을 원하는 데이터를 생성
- 모델이 데이터를 잘 이해해서 그럴듯한 데이터를 생성하면 다행이지만 노이즈가 많은 데이터를 만들 수 있는 가능성이 많아서 관심도는 떨어지고 있다. (애초에 데이터를 생성하는 일은 그리 쉽지 않은 편..)
2. Stream-based Selective Sampling
- 데이터 distribution에서 sample을 하나씩 불러와서 label의 필요성을 모델이 결정
- 예를 들어, uncertainty 영역을 계산해 해당 영역 안의 데이터로만 query 하거나 정보가 일정 기준 이상인 경우에만 선택해 query 할 수 있다.
3. Pool-based Sampling
- 모델이 label이 없는 아주 큰 data pool에서 query 한다.
- 데이터는 쉽게 수집할 수 있지만, labeling 비용이 많이 드는 경우 적합한 방식이다. (예시 : 이미지 및 영상 분류, 음성 인식 등)
Stream-based Selective Sampling과 Pool-based Sampling 차이
- Stream-based Selective Sampling 은 전체 데이터를 고려하지 않고 데이터를 순차적으로 스캔해서 query를 결정한다.
- Pool-based Sampling 은 전체 데이터 집합을 평가하고 정보가 많은 query를 selective 하게 추출한다.
Query 전략
Active learning에서 핵심이라고 할 수 있는 Query는 어떻게 선택할 수 있을까? 가장 일반적인 Query 전략들을 살펴보자.
1. Uncertainty Sampling
- Uncertainty Sampling은 모델이 가장 확신이 없는 데이터를 query 하는 방법
- 이진 분류에서는 모델이 예측한 값이 (예를 들어, 동전 던지기처럼) 50:50에 가까운 데이터를 선택한다.
- 다중 클래스 문제에서는 top confidence와 maximum entropy를 주로 사용한다.
Top confidence
- top confidence는 모델이 예측한 label의 확률을 보고, 확률이 가장 낮은 data를 선택하는 방식
- 특정 데이터를 보고 '이 데이터는 A class일 확률이 90%'처럼 가장 높은 확률로 예측한 label이 얼마나 확실한 지를 보고, 확률이 51%밖에 되지 않는 헷갈리는 데이터를 선택해서 label을 요청하는 방식
Maximum entropy
- maximum entropy는 모든 label에 대해 확률을 고려해 모델이 가장 불확실한 data를 찾는 방식
- 예를 들어, 어떤 데이터가 A class일 확률이 33%, B class일 확률이 33%, C class일 확률이 34%라면, 모델이 이 데이터에 대해 확신을 가지지 못하기 때문에 label을 요청한다.
결론은 '헷갈리는 데이터는 oracle(사람)에게 label 요청하겠다.'
2. Query By Committee (QBC)
- 또 다른 유명한 query 전략은 QBC이다.
- 여러 개의 모델을 학습시켜 모델들 간의 데이터에 대한 의견 불일치를 바탕으로 labeling 할 데이터를 선택한다.
- 한 데이터에 대해 모델들이 다른 예측을 한다면, 그 데이터는 모델이 헷갈리는 데이터이기 때문에 labeling 하는 것이 유용하다는 의미이다.
그 외의 전략들
위 두 가지 방법은 고전적인 Active learning에서 가장 인기 있는 방법이지만, 수년간 다양한 방법들이 개발되었다. 그 외의 전략도 살펴보자.
Expected Model Change
- Expected Model Change는 모델에 큰 변화를 줄 수 있는 데이터를 선택하는 방식
- 예를 들어, 신경망에서는 기울기를 계산해 모델의 예측이 얼마나 변할지 측정할 수 있는데, 이때 기울기 변화가 가장 큰 데이터를 골라 label을 요청하는 방식
- 이유: 기존의 학습 방향을 크게 개선하거나 바꿀 수 있는 중요한 데이터를 학습하게 되어 성능이 더 좋아질 수 있다.
Density Weighted Methods
- Density Weighted Methods는 데이터가 많이 밀집된 영역에서 모델이 불확실하다고 생각하는 데이터를 선택, 불확실하다고 해서 무조건 선택하는 것이 아니라 outliers는 제외한다.
- 이유: 데이터 분포 전체를 잘 반영할 수 있다. (representative)
마무리
- 모델이 주어진 데이터에 직접 질문을 할 수 있다면 labeling 비용을 줄여 기존의 지도 학습의 문제점을 보완할 수 있다.
- 글에서 설명하는 active learning 은 기본적인 개념으로 실제 활용에서는 제약이 있을 수 있다.
Reference
- Active Learning Review | Discriminative Active Learning (dsgissin.github.io)
- The Way Machines Should See: Active Learning Literature Survey (Settles, 2010) - Part1 (visionexperiments.blogspot.com)
- 현재 관련 분야를 공부하고 있는 전문가가 아닌 학생이기 때문에 틀린 내용이 있을 수 있습니다.
- 오타와 틀린 부분을 댓글로 알려주시면 수정하도록 하겠습니다.
'AI study > Machine learning' 카테고리의 다른 글
| 혼동행렬 (Confusion matrix) (0) | 2025.09.09 |
|---|